Introduction
This is an ongoing project in collaboration with Jules Françoise, in which we are trying to teach a neural network to generate beat-synchronous dance movements for a given song, as well as matching movement patterns with the musical patterns. We have created a database of synchronized groove moves/songs for the training data.
Rather than a supervised approach, we are treating this as an unsupervised learning problem. For each song, we extract the audio descriptors and train a multi-modal neural network both the audio descriptors and joint rotations.
I will be updating this page as we make progress...
The Approach
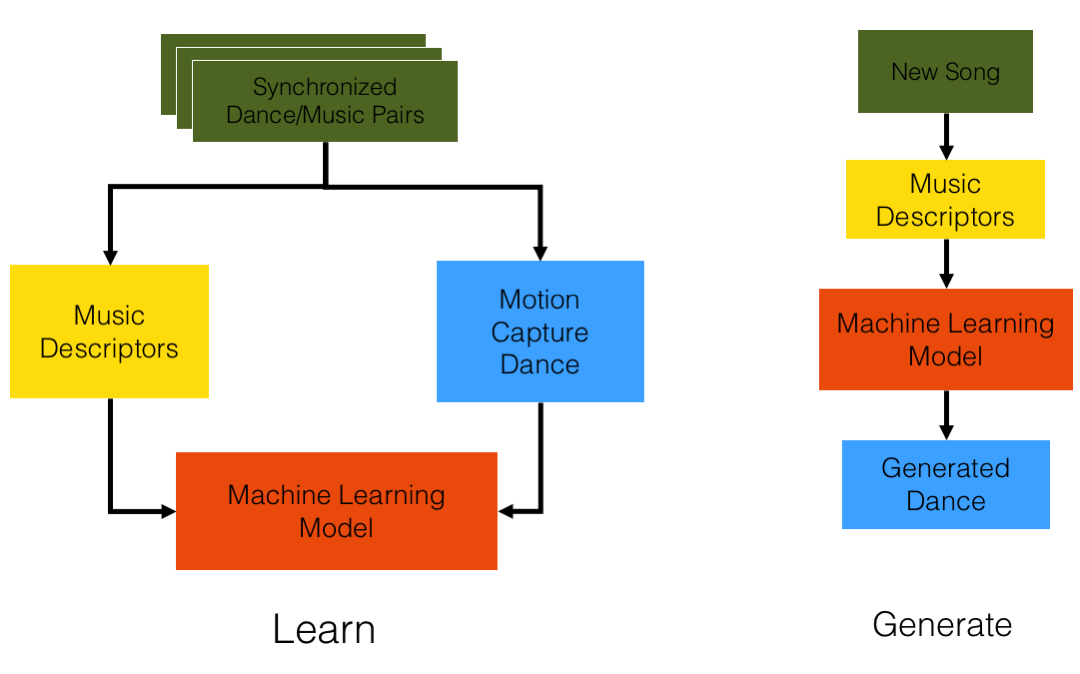
Training Data
Preliminary Results - April 2017
As submitted to the Workshop on Machine Learning for Creativity: PDF.
Learning and Generating Movement Patterns
FCRBM - Labeled Mocap Segments - No Audio
Hidden Units: 150 | Factors: 400 | Order: 6 | Frame Rate: 30
16-Dimensional, One-hot-encoded Labels
Pattern 4 • Pattern 5 • Pattern 6 • Pattern 7 • Pattern 8 • Pattern 9 • Pattern 10 • Pattern 11 • Pattern 12 • Pattern 13 • Pattern 14 • Pattern 15
* The rest of the labels (1, 2, 3, and 16) either represented non-moving portions of the mocap sequence, e.g., the beginnning, or did not cause the model to learn any patterns.
Dancing with Training Songs
FCRBM - Cooked Features
Hidden Units: 500 | Factors: 500 | Order: 30 | Frame Rate: 60
Audio Features: 84-Dimensions:
low-level features (RMS level, Bark bands)
spectral features (energy in low/middle/high frequencies, spectral centroid, spectral spread, spectral skewness, spectral kurtosis, spectral rolloff, spectral crest, spectral flux, spectral complexity),
timbral Features (Mel-Frequency Cepstral Coefficients, Tristimulus),
melodic Features (pitch, pitch salience and confidence, inharmonicity, dissonance).
Based on audio track 1:
Output 1 •
Output 2 •
Output 3
Based on audio track 2:
Output 4 •
Output 5 •
Output 6
Based on audio track 3:
Output 7 •
Output 8 •
Output 9
Dancing with Unheard Songs
-
FCRBM - Cooked Features
Hidden Units: 500 | Factors: 500 | Order: 30 | Frame Rate: 60
Audio Features: 84-Dimensions:
low-level features (RMS level, Bark bands)
spectral features (energy in low/middle/high frequencies, spectral centroid, spectral spread, spectral skewness, spectral kurtosis, spectral rolloff, spectral crest, spectral flux, spectral complexity),
timbral Features (Mel-Frequency Cepstral Coefficients, Tristimulus),
melodic Features (pitch, pitch salience and confidence, inharmonicity, dissonance).
Output 1 • Output 2 • Output 3 • Output 4 • Output 5 • Output 6
Fun Outputs
Fun 1 • Fun 2 • Fun 3 • Fun 4 • Fun 5
Publications
- Omid Alemi, Jules Françoise, and Philippe Pasquier. "GrooveNet: Real-Time Music-Driven Dance Movement Generation using Artificial Neural Networks". Accepted to the Workshop on Machine Learning for Creativity, 23rd ACM SIGKDD Conference on Knowledge Discovery and Data Mining. Halifax, Nova Scotia - Canada. 2017. PDF.